GenBank Upload Pipeline 1: GenBank Submission Portal
The GenBank Submission Portal on the NCBI website must be used to submit metazoan (multicellular) mtCOI and/or any rRNA sequences (such as 18S, 16S, 23S, 28S, ITS, etc.), as GenBank no longer supports submissions of these markers through the Geneious Prime GenBank Submission plugin. This plugin can still be used to submit all other markers. See GenBank Upload Pipeline 2: Geneious Prime GenBank Submission Tool for a detailed step by step of how to use the plugin.
To demonstrate GenBank submission via the Submission Portal, a batch of COX1 Diptera barcodes will be used as an example.
Navigate to the NCBI Submission Portal: https://submit.ncbi.nlm.nih.gov/
Click on “Log in” in the upper right corner. NCBI now uses third party accounts to sign in, so either a Google or an SI.gov username and password should work.
Back on the Submission Portal page, in the search box, type “GenBank” and the link to the GenBank submission tool will appear as one of the suggested options.
On the first page of the GenBank submission process, it is possible to click through the headings on the left of the “What You Should Expect” section to learn more about the requirements.
When ready to continue, click the “Submit” button.
Click the “New submission” button.
This will lead to a series of 8 tabs where data will be filled in or uploaded. If there is organism information that is new to NCBI, an extra “Organism” tab will appear later on. The tabs are detailed below.
Submission Type Tab
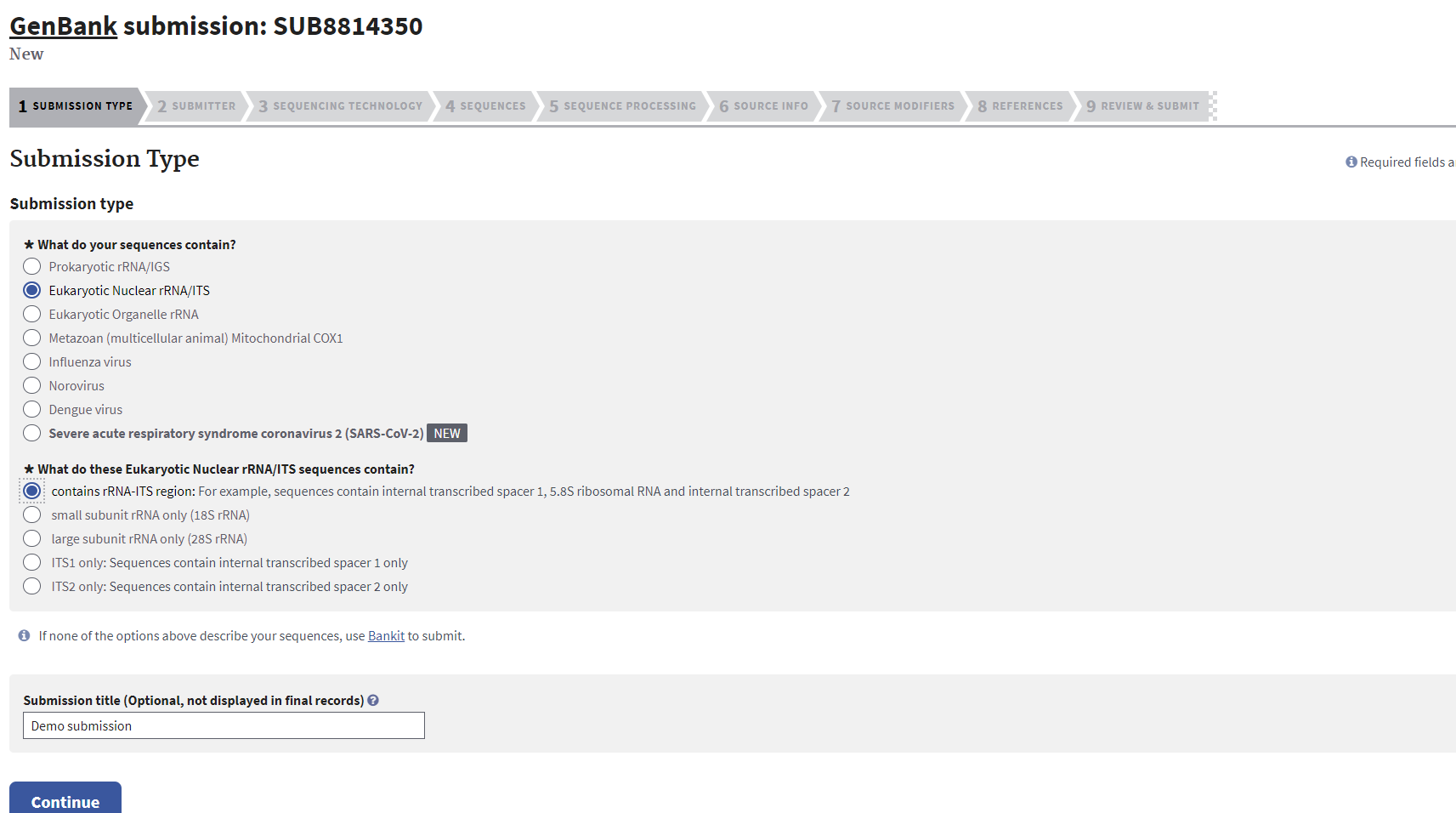
Choose the region to be submitted and specify any further details as necessary. Specifying a “Submission title” can be useful for organizing submissions within one’s NCBI account. Click “Continue”.
Submitter Tab
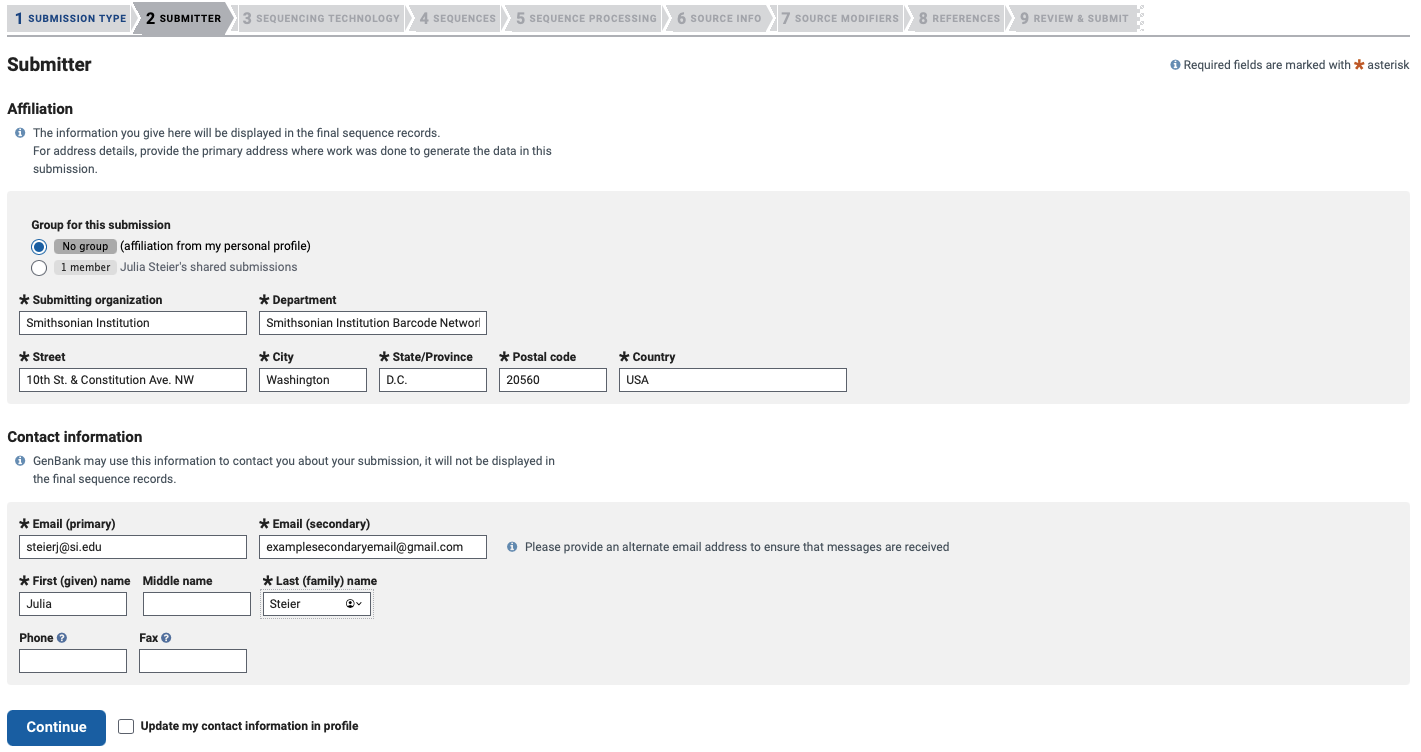
Fill in the submitter’s affiliated institution and contact information. Click “Continue”.
Sequencing Technology Tab
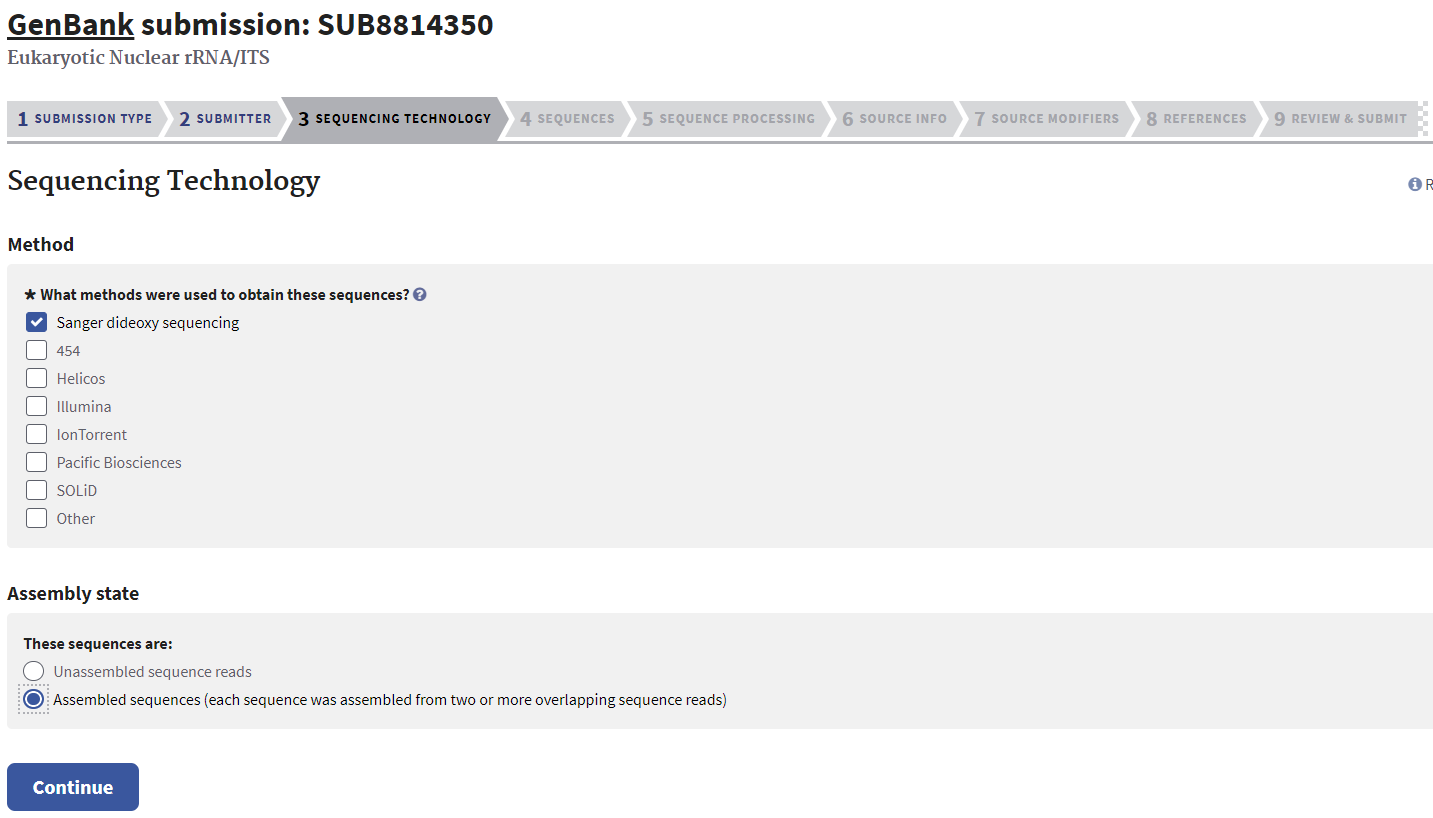
Indicate the technology used to obtain sequences and whether sequences are assembled or unassembled.
Sequences Tab
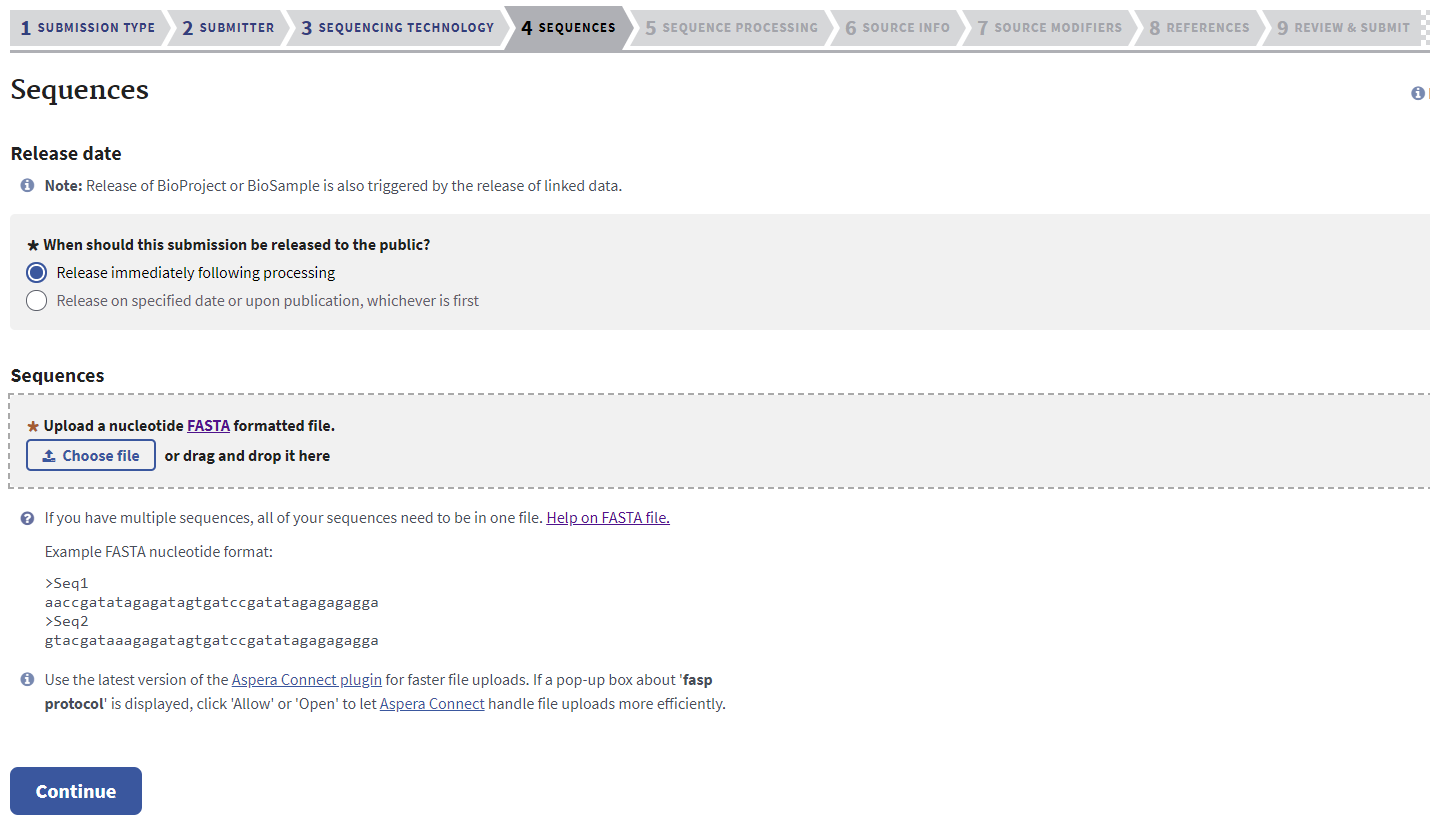
Indicate when sequences should be released. SIBN funded projects require that sequences be released as soon as possible and no later than 12 months of sequence generation. Please see the Rapid Data Release Policy page for more information and contact SIBN staff with any further questions about this requirement.
Sequences need to be uploaded in a FASTA file. Sequences can be exported in this format from Geneious Prime using the Exporting Sequences in FASTA format instructions.
Before exporting from Geneious Prime, ensure that local Geneious files have been renamed by the voucherCatalogNumber (the DwC triplet or doublet from GEOME FIMS) using the Using the Batch Rename Function instructions.
Note
This assumes that voucher numbers represented by voucherCatalogNumber are unique across the sequences to be submitted. If this is not the case, another unique value such as tissueBarcode may be used to name sequences with the Batch Rename function.
Once the FASTA file has been exported from Geneious Prime, follow the instructions on the GenBank Submission Portal to upload. Click “Continue”.
The Submission Portal now processes and validates the uploaded sequences to ensure the correct sequence type has been selected and that there are no stop codons, if submitting COI. If any sequences are flagged, the Portal will create a downloadable report identifying problematic sequences. These need to be fixed before proceeding.
Source Information Tab
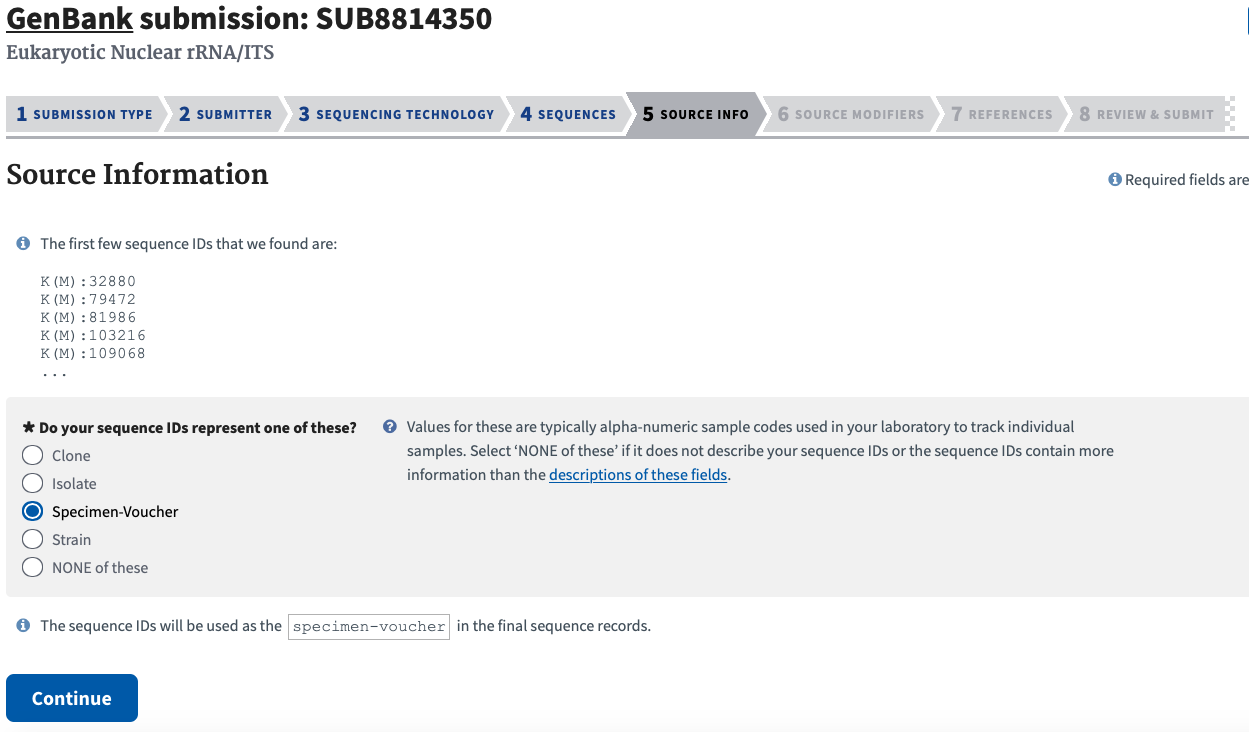
As most SIBN funded projects generate sequence data from DNA derived from accessioned vouchers, indicate that sequence IDs (sequence name from Geneious Prime) represent the Specimen-voucher in the final sequence records in GenBank. If the sequences were named by their voucherCatalogNumber (DwC triplet or doublet), this will allow GenBank to form a link to the collection of origin for the specimen sequenced.
Note
If sequences were named in the previous step by a value other than the DwC voucher number, then indicate that sequence IDs (sequence name from Geneious Prime) represent Isolate. DwC voucher number will need to be added with the rest of the Source Modifiers in the Source Modifiers tab, described below.
Source Modifiers Tab
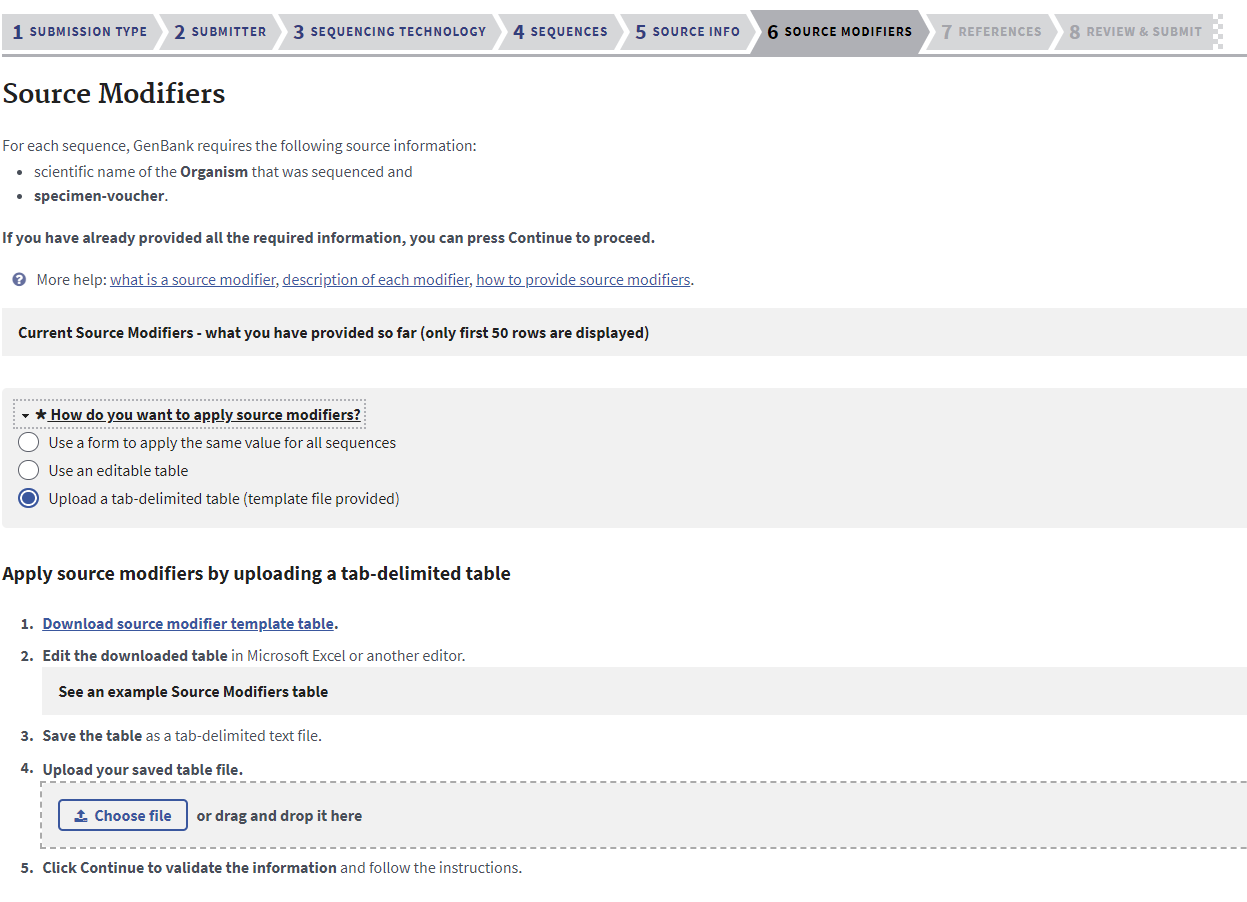
The rest of the sequence metadata (or “Source Modifiers” in GenBank) now need to be uploaded. The easiest way to do this in bulk is with a tsv file. This tsv file can be exported from Geneious Prime in a similar way as the sequence FASTA file.
To export the sequence metadata from Geneious Prime, see Exporting Sequence Metadata in TSV format for instructions. Select the metadata fields for export from the “Field in Geneious Prime” column in the below table. Only voucherCatalogNumber (or value used to name sequences in the FASTA file) and scientificName are essential for submission through the Portal, but the other listed fields are strongly recommended to create high quality barcode records.
Once the metadata are exported as a tsv file, in Excel or a text editor, change the column headers to the corresponding GenBank Source Modifier names so the Submission Portal will recognize them. See below table for corresponding names.
Field in Geneious Prime |
GenBank modifier field |
|---|---|
voucherCatalogNumber* |
Sequence_ID** |
scientificName |
Organism |
collectorList |
Collected_by |
genbankCountry |
geo_loc_name |
genbankDate |
Collection_date |
genbankLatLng |
Lat_Lon |
Sequencing Primer: Forward Sequencing Primer Name |
Fwd_primer_name |
Sequencing Primer: Forward Sequencing Primer Sequence |
Fwd_primer_seq |
Sequencing Primer: Reverse Sequencing Primer Name |
Rev_primer_name |
Sequencing Primer: Reverse Sequencing Primer Sequence |
Rev_primer_seq |
* voucherCatalogNumber or value used to name sequences in FASTA file
** Sequence_ID will translate to Specimen_voucher or Isolate, depending on what was chosen in the previous tab of the portal
Further Source Modifier Notes for Consideration:
The Geneious Prime fields genbankCountry, genbankDate, and genbankLatLng are generated by the Biocode LIMS Plugin to GenBank accepted format by consolidating applicable fields from GEOME FIMS.
Be sure, after metadata export, that numeric date data are not missing leading zeros (ex: 2022-03-09 for the YYYY-MM-DD format).
Remove any latitude/longitude data that was marked as “unknown”. When given blank data for the latitude and longitude fields in GEOME FIMS, Biocode LIMS will consolidate the blanks as “unknown” in the genbankLatLng field, but the GenBank Submission Portal will not accept this.
If voucherCatalogNumber was not used as the Sequence ID and indicated as the Specimen_voucher (i.e. if another unique value was used to name sequences in FASTA file and were indicated as the Isolate in the previous step), then Specimen_voucher needs to be included in the tsv file as a data field containing the DwC triplet or doublet for each sequence’s voucher.
Any number of additional fields from the FIMS and LIMS with the appropriate GenBank source modifier name may be added to the tsv file. Examples of other fields from GenBank that might be added here are “Host”, “Isolate”, or “Bio_material”, depending on the nature of the samples and metadata. The “Notes” GenBank field can be added too if notes on the taxonomic confidence kept in the LIMS field “Assembly Notes” need to be added to the GenBank records.
Regarding BioProjects: If sequences being submitted will be organized within a BioProject that has already been created, it is possible to add that to the tsv file at this stage. Simply add the column header “BioProject” and list the PRNJ BioProject number for each sequence. To create a BioProject ahead of time and for any further information on associating barcode accessions with GenBank Bioprojects, see the NCBI BioProjects instructions.
While it is recommended to export the tsv metadata file from Geneious Prime, a tsv file for upload may also be obtained from reformatting data directly from GEOME FIMS or from a local spreadsheet if GEOME FIMS was never used, but remember to include primer name and sequence data and to format geo_loc_name, Collection_date, and Lat_Lon data according to GenBank standards. For more information or examples of how these data should be formatted, see the GenBank recommendations.
Upload the tsv file as a tab-delimited table to the GenBank Submission Portal. Click “Continue”.
After clicking Continue, the Portal will validate the metadata table and check if the Sequence IDs provided in the table match with the sequence FASTA file. The Portal will note anything it finds problematic such as data formatting or names not in the NCBI taxonomy database. Any data formatting problems will need to be corrected before proceeding.
Organism Info Tab
Skip to the next tab instructions if no unknown organism names were detected.
If any names associated with the sequences were not in the NCBI taxonomy database, the “Organism Info” tab will pop up in the Submission Portal asking for further information to confirm that the new names are valid.
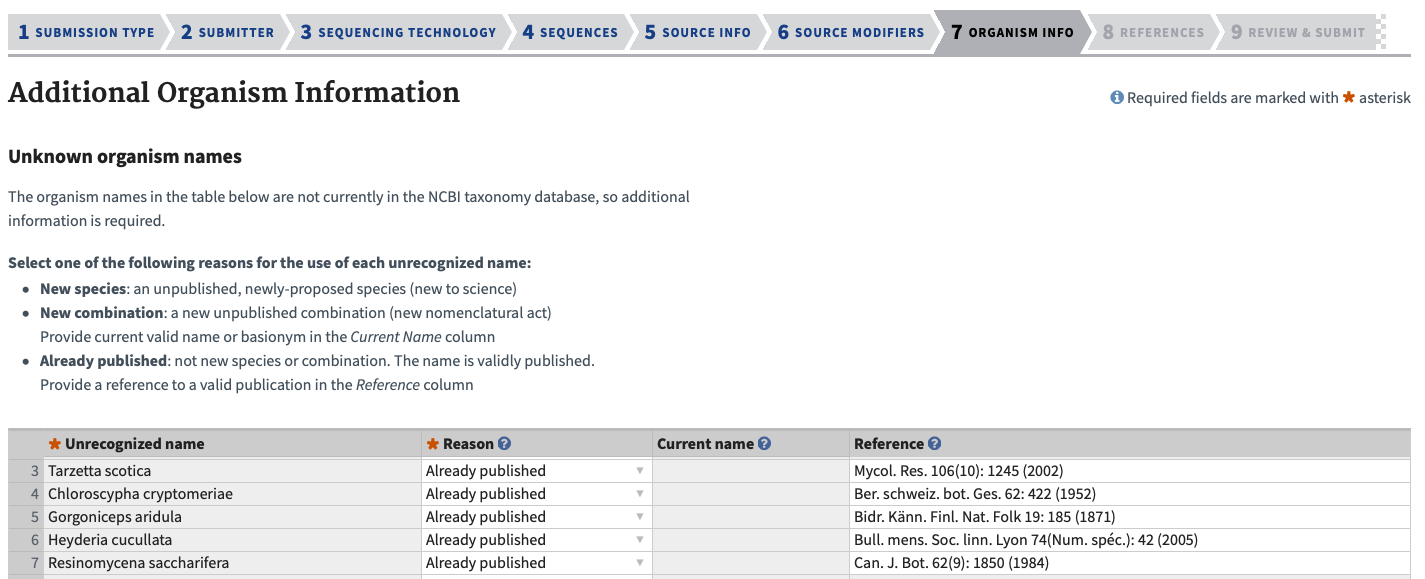
It could be that old names were used or typos were present in the metadata - in this case, return to the previous Source Modifier tab and upload a new tsv file with the corrected names.
Fill out the reason for each new name, whether it is a New Species, New Combination and Current Name, or Already Published and Reference.
New non-specific taxon names (e.g. Amphiesma sp.) and morphospecies names may be submitted as a “New species”.
When submitting COI sequences, also indicate “Mitochondrial Genetic Code” for new names to NCBI. For more information on NCBI genetic codes see their webpage. When submitting rRNA sequences, this will not be asked.
Once all details for unknown names are filled out, click “Continue”.
References Tab
This tab is used to fill in details on who produced the sequences and any relevant publication data. If a publication is or will be associated with the sequences, always include at least one publication author as a sequence author. Important: Only sequence authors can edit the records in GenBank.
For records associated with USNM collections, SIBN strongly recommends that the relevant departmental Data Manager and/or the departmental Collections Manager are included in the Sequence Authors list as this can assist with updates if required in the future. Discussions should be held with the relevant departmental staff to discuss the sequence authors on the GenBank records.
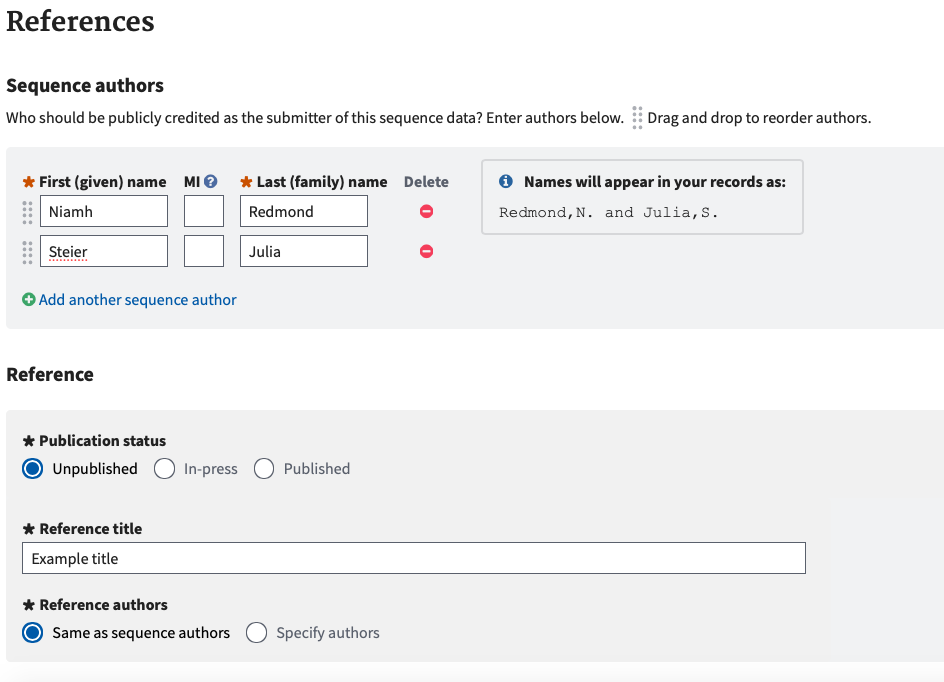
Once publication details are filled in, click “Continue”.
Review and Submit
This last tab provides a review of all data entries both raw and how it will be displayed in the GenBank records. This is the last opportunity to change anything before submitting.
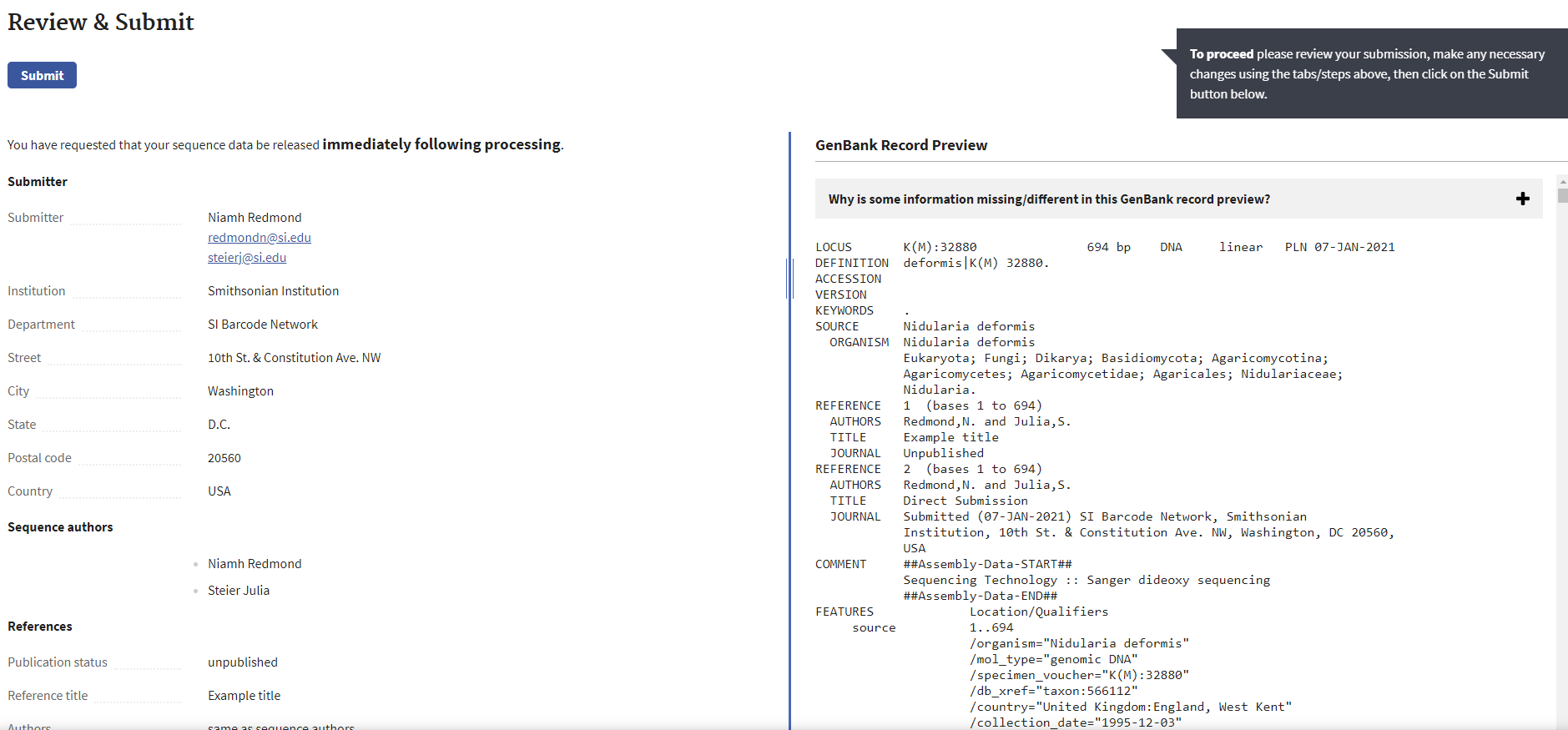
Once all details are confirmed to be correct, click “Submit”.
After Submission
A few days after submission, an email should be received from the NCBI admin team confirming the submission and assigning GenBank accession numbers to each of the sequences. Any issues that may have come up during post-submission processing will also be addressed.
Accession numbers should be reported back to the relevant departmental staff so they can be linked to the genetic sample records in EMu. If the sequencing project was funded by SIBN, please also report accession numbers back to the SIBN project manager.